jBPM 5 includes a completely new API based on the Drools Project, and adds a number of key features including support for the BPMN 2.0 specification, Eclipse tooling for developers, and web-based tooling for business users.
First a brief history of jBPM:
jBPM has gone through 3 main releases:
jBPM3 offers a process engine supporting the native jPDL language execution with management a web based monitoring console. At the moment this is the only release supported by Red Hat although it’s in maintenance mode.
jBPM4 offers both the native jPDL language and support and BPMN 2.0 execution engine. There are however no plans by Redhat to support this release at the moment.
jBPM5 offers a generic process engine supporting native BPMN 2.0 execution along with a powerful rules and event engine integration. It also offers an advanced monitoring and management web based console.
So the first important feature is jBPM 5 is that it focuses on BPMN 2 as the process definition language. BPMN 2 standardizes the visual representation of business processes as well as their underlying XML representation, significantly improving the interoperability between modeling tools (as for example our web-based and Eclipse-based designers). The BPMN 2 standard is solid and extensible, so that new elements and attributes can be introduced when necessary.
In jBPM5, you can actually model more using BPMN 2 than you ever could with jPDL for example, and at a higher level. As a result, jBPM5 does no longer support the direct execution of jPDL, although a migration from jPDL to BPMN 2 has been developed.
The second main feature of jBPM 5 is the rules engine. jBPM has been conceived having in mind the code base of Drools Flow project (as far as it concerns the process flow) and Drools expert. The latter one, provides a solid rules engine which allows applying inferences on our business processes, handling processes exceptional paths using rules or mixing events rules and processes using a single Api..
It has proven that such features like rules engine can bring great value in the long run to better manage the complexity of real-life use cases. This knowledge has been combined with the experience built up in jBPM over the last few years and has resulted in jBPM 5. The vision of jBPM however hasn’t changed, rather it has been extended.
So altough jBPM 5 has been released just in December 2010, it can be considered a mature product as it inherits a code base from Drools Flow which has been exensively tested for over 3 years.
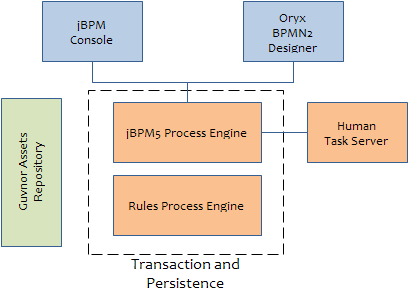
Thir third innovative feature is the new Human Task Servers. jBPM 5 uses a pluggable component to handle the lifecycle of human tasks. This component is based on the Web Services Human Task specification. It defines the data structure to store information about the Human Tasks which are contained in the processes without knowing about the process itself.
At runtime the jBPM 5 engine loads the XML process definition to an Object Model that contains the process structure. Based on this project structure, we can create new Process Instances that represent living process executions. In order to understand thr jBPM 5 Api you need to catch the following basic definitions:
The Knowlege Base is a repository of all the application’s knowledge definitions. It may contain rules, processes, functions, and type models. The Knowledge Base itself does not contain instance data, known as facts;
To create a knowledge base, use a KnowledgeBuilder to load processes from various resources (for example from the classpath or from file system), and then create a new knowledge base from that builder.
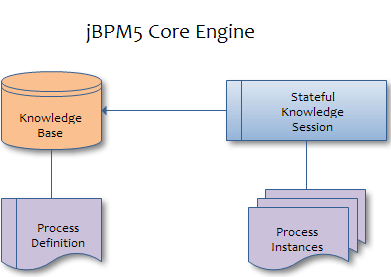
Once you’ve loaded your knowledge base, you should create a session to interact with the engine. This session can then be used to start new processes, signal events, etc.
public static final void main(String[] args) throws Exception {
// load up the knowledge base
KnowledgeBase kbase = readKnowledgeBase();
StatefulKnowledgeSession ksession = kbase.newStatefulKnowledgeSession();
ksession.startProcess("com.sample.bpmn.hello");
}
private static KnowledgeBase readKnowledgeBase() throws Exception {
KnowledgeBuilder kbuilder = KnowledgeBuilderFactory.newKnowledgeBuilder();
kbuilder.add(ResourceFactory.newClassPathResource("sample.bpmn"), ResourceType.BPMN2);
return kbuilder.newKnowledgeBase();
}
Creating the KnowlegeBase can be heavy, whereas session creation is very light, so it is recommended that Knowledge Bases be cached where possible to allow for repeated session creation.