This tutorial contains a large collection of Performance tuning tips for JBoss Application Server version 5.
Please note: There is a more recent version of this article for WildFly application server. JBoss Performance Tuning Tips and Hints
Tune the garbage collector
One strength of the J2SE platform is that it shields the developer from the complexity of memory allocation. However, once garbage collection is the principal bottleneck, it is worth understanding some aspects of this hidden implementation
An object is considered garbage when it can no longer be reached from any pointer in the running program. The most straightforward garbage collection algorithms simply iterate over every reachable object. Any objects left over are then considered garbage. The time this approach takes is proportional to the number of live objects,
The complete address space reserved for object memory can be divided into the young and tenured generations.
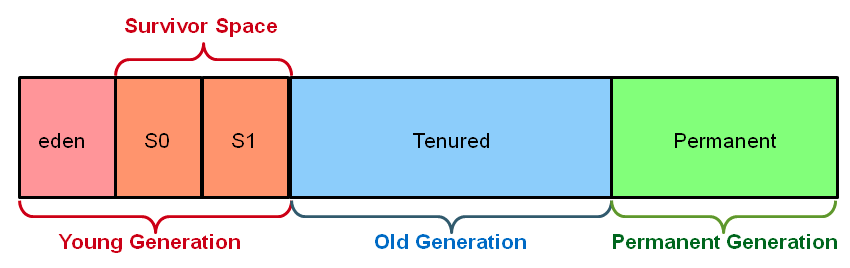
The young generation consists of eden and two survivor spaces. Most objects are initially allocated in eden. One survivor space is empty at any time, and serves as the destination of any live objects in eden and the other survivor space during the next copying collection. Objects are copied between survivor spaces in this way until they are old enough to be tenured (copied to the tenured generation).
A third generation closely related to the tenured generation is the permanent generation which holds data needed by the virtual machine to describe objects that do not have an equivalence at the Java language level. For example objects describing classes and methods are stored in the permanent generation
Use the the command line option -verbose:gc causes information about the heap and garbage collection to be printed at each collection. For example, here is output from a large server application:

It’s demonstrated that an application that spends 10% of its time in garbage collection can lose 75% of its throughput when scaled out to 32 processors
(http://java.sun.com/javase/technologies/hotspot/gc/gc_tuning_6.html)
Set -Xms and -Xmx to the same value
By default, the virtual machine grows or shrinks the heap at each collection to try to keep the proportion of free space to live objects at each collection within a specific range. Setting -Xms and -Xmx to the same value. This increase predictability by removing the most important sizing decision from the virtual machine.
Use server VM
The server JVM is better suited to longer running applications. To enable it simply set the -server option on the command line.
Turn off distributed gc
The RMI system provides a reference counting distributed garbage collection algorithm. This system works by having the server keep track of which clients have requested access to remote objects running on the server. When a reference is made, the server marks the object as “dirty” and when a client drops the reference, it is marked as being “clean.”. However this system is quite expensive and by default runs every minute.
Set it to run every 30 minute at least
-Dsun.rmi.dgc.client.gcInterval=1800000 -Dsun.rmi.dgc.server.gcInterval=1800000
Turn on parallel gc
If you have multiple proessors you can do your garbage collection with multiple threads. By default the parallel collector runs a collection thread per processor, that is if you have an 8 processor box then you’ll garbage collect your data with 8 threads. In order to turn on the parallel collector use the flag –XX:+UseParallelGC. You can also specify how many threads you want to dedicate to garbage collection using the flag -XX:ParallelGCThreads=8.
Don’t use Huge heaps, use a cluster
More JVMs/smaller heaps can outperform fewer JVMs/Larger Heaps. So instead of huge heaps, use additional server nodes. Set up a JBoss cluster and balance work between nodes.
Don’t choose an heap larger then 70% of your OS memory
Choose a maximum heap size not more then 70% of the memory to avoid excessive page faults and thrashing.
Tune the Heap ratio
This is one of most important tuning factor: the heap ratio. The heap ratio specifies how the amount of the total heap will be partitioned between the young and the tenured space. What happens if you have lots of long lived data (cached data, collections ) ? maybe you’re in this situation:
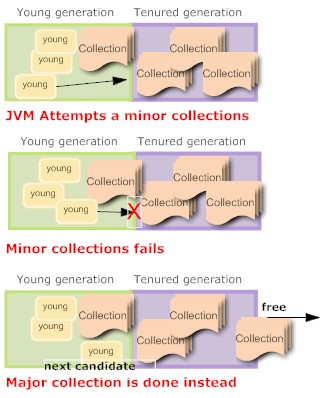
The problem here is that the long lived data overflows the tenured generation. When a collection is needed the tenured generation is basically full of live data. Much of the young generation is also filled with long lived data. The result was that a minor collection could not be done successfully (there wasn’t enough room in the tenured generation for the anticipated promotions out of the young generation) so a major collection was done.
The major collection worked fine, but the results again was that the tenured generation was full of long lived data and there was long lived data in the young generation. There was also free space in the young generation for more allocations, but the next collection was again destined to be a major collection.
This will eventually bring your application to crawl !!!!!
By decreasing the space in the young generation and putting that space into the tenured generation (a value of NewRatio larger than the default value was chosen), there was enough room in the tenured generation to hold all the long lived data and also space to support minor collections. This particular application used lots of short lived objects so after the fix mostly minor collections were done.
NewRatio is a flag that specifies the amount of the total heap that will be partitioned into the young generation. It’s the tenured-generation-size / young-generation-size. For example, setting -XX:NewRatio=3 means that the ratio between the young and tenured generation is 1:3
If you want a more precise control over the young generation : NewSize is the initial size of the young generation, MaxNewSize will specify the maximum size of the young generation
What is the recommeded heap ratios ? Set the tenured generation to be approximately two times the size of the young generation.
This recommendation is only a starting point, you have to tune from there and to do that you have to gather and analyze the garbage collection statistics.
Monitor the free memory with monitors and snapshots
Check out our Monitoring Tips.
Tune the Operating System
Each operating system sets default tuning parameters differently. For Windows platforms, the default settings are usually sufficient. However, the UNIX and Linux operating systems usually need to be tuned appropriately
Lots of Requests ? check JBoss thread pool
JBoss thread pool is defined into conf/jboss-service.xml
<mbean code="org.jboss.util.threadpool.BasicThreadPool" name="jboss.system:service=ThreadPool"> <attribute name="Name">JBoss System Threads</attribute> <attribute name="ThreadGroupName">System Threads</attribute> <attribute name="KeepAliveTime">60000</attribute> <attribute name="MaximumPoolSize">10</attribute> <attribute name="MaximumQueueSize">1000</attribute> <attribute name="BlockingMode">run</attribute> </mbean>
For most applications this defaults will just work well, however if you are running an application with issues lots of requests to jboss (such as EJB invocations) then monitor your thread pool. Open the Web Console and look for the MBean jboss.system:service=ThreadPool.
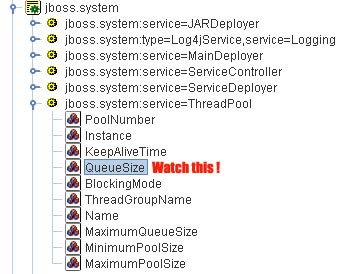
Start a monitor on the QueueSize parameter. Have you got a QueueSize which reaches MaximumPoolSize ? then probably you need to set a higher MaximumPoolSize pool size attribute
Watchout! Speak at first with your sysadmin and ensure that the CPU capacity support the increase in threads.
Watchout! if your threads make use of JDBC connections you’ll probably need to increase also the JDBC connection pool accordingly. Also verify that your HTTP connector is enabled to handle that amount of requests.
Check the Embedded web container
JBoss supports connectors for http, https, and ajp. The configuration file is server.xml and it’s deployed in the root of JBoss web container (In JBoss 4.2.0 it’s: “JBOSS_HOME\server\default\deploy\jboss-web.deployer”)
<Connector port="8080" address="${jboss.bind.address}"
maxThreads="250" maxHttpHeaderSize="8192"
emptySessionPath="true" protocol="HTTP/1.1"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" />
The underlying HTTP connector of JBoss needs to be fine tuned for production settings. The important parameters are:
maxThreads – This indicates the maximum number of threads to be allocated for handling client HTTP requests. This figure corresponds to the concurrent users that are going to access the application. Depending on the machine configuration, there is a physical limit beyond which you will need to do clustering.
acceptCount – This is the number of request threads that are put in request queue when all available threads are used. When this exceeds, client machines get a request timeout response.
compression – If you set this attribute to “force”, the content will be compressed by JBoss and will be send to browser. Browser will extract it and display the page on screen. Enabling compression can substantially reduce bandwidth requirements of your application.
So how do you know if it’s necessary to raise your maxThreads number ? again open the web console and look for the MBean jboss.web:name=http-127.0.0.1-8080,type=ThreadPool. The key attribute is currentThreadsBusy. If it’s about 70-80% of the the maxThreads you should consider raising the number of maxThreads.

Watch out! if you increase the maxThreads count you need to raise your JBoss Thread pool accordingly.
Turn off JSP Compilation in production
JBoss application server regularly checks whether a JSP requires compilation to a servlet before executing a JSP. In a production server, JSP files won’t change and hence you can configure the settings for increased performance.
Open the web.xml in deploy/jboss-web.deployer/conf folder. Look for the jsp servlet in the file and modify the following XML fragment as given below:
<init-param> <param-name>development</param-name> <param-value>false</param-value> </init-param> <init-param> <param-name>checkInterval</param-name> <param-value>300</param-value> </init-param>
Lots of EJB requests ? switch to the PoolInvoker
JBoss uses RMI for EJB communication and by default creates a single thread for every incoming request.
When the number of requests is very large this could be a bottleneck. However you can switch from the standard jrmp service invoker to the pool invoker. How to do it ? open standardjboss.xml and find the following fragment:
<invoker-mbean>jboss:service=invoker,type=jrmp</invoker-mbean>
On JBoss 4.x you should find 4 occurrences of it: stateless-rmi-invoker, clustered-stateless-rmi-invoker, stateful-rmi-invoker,entity-rmi-invoker. Now replace this fragment with :
<invoker-mbean>jboss:service=invoker,type=pooled</invoker-mbean>
Notice you can even have a mixed environment: that is stateless invocation managed by the pool and all others by jrmp.
If you want to change the default attributes of your pool then open jboss-service.xml
<mbean code="org.jboss.invocation.pooled.server.PooledInvoker"
name="jboss:service=invoker,type=pooled">
<attribute name="NumAcceptThreads">1</attribute>
<attribute name="MaxPoolSize">300</attribute>
<attribute name="ClientMaxPoolSize">300</attribute>
<attribute name="SocketTimeout">60000</attribute>
<attribute name="ServerBindAddress">${jboss.bind.address}</attribute>
<attribute name="ServerBindPort">4445</attribute>
<attribute name="ClientConnectAddress">${jboss.bind.address}</attribute>
<attribute name="ClientConnectPort">0</attribute>
<attribute name="ClientRetryCount">1</attribute>
<attribute name="EnableTcpNoDelay">false</attribute>
</mbean>
There are two key attributes for the PooledInvoker in regards to how many threads are used in processing requests. The first is the NumAcceptThreads attribute. The value for this attribute will determine how many threads are created to listen for incoming requests. These threads will be the ones that call the accept() method of the server socket (which is a blocking call and will wait there till data is received on the network interface for the server socket).
The MaxPoolSize is the other key factor: it’s the size of the pool containing the ServerThreads .
How can MaxPoolSize become a bottleneck ? if the accept thread can not get a worker thread from the pool and the pool size has reached the MaxPoolSize value, it will wait for one to become available (instead of creating a new one).
Have you got readonly Entity Beans ? tell it to JBoss
JBoss offers a way to handle this situation by defining either an entire EJB as being “read-only” or simply as a subset of its methods. When accessing a read-only method (or EJB), while JBoss still prevents concurrent access to the same bean instance, the bean will not be enrolled in the transaction and will not be locked during the whole transaction lifetime. Consequently, other transactions can directly use it for their own work.
<enterprise-beans>
<entity>
<ejb-name>MyEntity</ejb-name>
<method-attributes>
<method>
<method-name>get*</method-name>
<read-only>true</read-only>
</method>
</method-attributes>
</entity>
</enterprise-beans>
Disable the hot deployer in production
See this tip: How to configure JBoss to disable hot deployment ?
Configure the EJB container to use cache, when possible.
If the EJB container has exclusive access to the persistent store, it doesn’t need to synchronize the in-memory bean state from the persistent store at the beginning of each transaction. So you could activate the so-called Commit-A option that caches entity bean state between transactions. In order to activate this option :
<jboss> <enterprise-beans> <container-configurations> <container-configuration extends= "Standard CMP 2.x EntityBean"> <container-name>CMP 2.x and Cache</container-name> <commit-option>A</commit-option> </container-configuration> </container-configurations> <entity> <ejb-name>MyEntity</ejb-name> <configuration-name CMP 2.x and Cache</configuration-name> <method-attributes> <method> <method-name>get*</method-name> <read-only>true</read-only> </method> <method-attributes> </entity> </jboss>
Use Cache invalidation in a Cluster for Commit Option A
Commit option A can boost your Entity Bean but what happens when running in a cluster ? in a cluster configuration more than one JBoss node will access the same database. Furthermore, they will not only read data, but may also update the db store.Consequently, we now have as many points of write access to the database as we have JBoss instances in the cluster.
For these scenarios, JBoss incorporates a handy tool: the cache invalidation framework. It provides automatic invalidation of cache entries in a single node or across a cluster of JBoss instances. As soon as an entity bean is modified on a node, an invalidation message is automatically sent to all related containers in the cluster and the related entry is removed from the cache. The next time the data is required by a node, it will not be found in cache, and will be reloaded from the database.
In order to activate it, add to your Entity Bean the cache-invalidation tag:
<entity>
<ejb-name>MyEntity</ejb-name>
<configuration-name>Standard CMP 2.x with cache invalidation</configuration-name>
<method-attributes>
<method>
<method-name>get*</method-name>
<read-only>true</read-only>
</method>
</method-attributes>
<cache-invalidation>True</cache-invalidation>
</entity>
Synchronize at commit time when possible.
The sync-on-commit-only element configures a performance optimization that will cause entity bean state to be synchronized with the database only at commit time. Normally the state of all the beans in a transaction would need to be synchronized when an finder method is called or when an remove method is called :
<container-configuration> <container-name>Standard Pessimistic CMP 2.x EntityBean</container-name> <call-logging>false</call-logging> <invoker-proxy-binding-name>entity-pooled-invoker</invoker-proxy-binding-name> <sync-on-commit-only>true</sync-on-commit-only> .... </container-configuration>
Use Prepared Statement Cache:
In JBoss, by default,prepared statements are not cached. To improve performance one can configure a prepared statement cache of an arbitrary size. You can use in your -ds.xml file the <prepared-statement-cache-size> : this is the number of prepared statements per connection to be kept open and reused in subsequent requests.
Remove services you don’t need
JBoss ships with lots of services, however you’ll seldom need to use them all. The service is usually deployed as *-service.xml under the deploy directory. Sometimes it’s also deployed as .sar/.rar archive. In order to remove the service, remove the file in the “Server/deploy” column. If needed remove also the relative libs stated under “Server/lib”
|
Service
|
Server/deploy
|
Server/lib
|
|
Mail service
|
mail-service.xml
|
mail-plugin.jar, mail.jar,activation.jar
|
|
Cache invalidation service
|
cache-invalidation-service.xml
|
|
|
J2EE client deployer service
|
client-deployer-service.xml
|
|
|
Hibernate HAR support
|
hibernate-deployer-service.xml
|
jboss-hibernate.jar, hibernate2.jar, cglib-full-2.0.1.jar, odmg-3.0.jar
|
|
HSQL DB
|
hsqldb-ds.xml
|
hsqldb-plugin.jar, hsqldb.jar
|
|
Default JMS Service
|
jms folder
|
jbossmq.jar
|
|
HTTP Invoker (tunnels RMI through HTTP)
|
http-invoker.sar
|
|
|
XA Datasources
|
jboss-xa-jdbc.rar
|
|
|
JMX Console
|
jmx-console.war
|
|
|
Web Console
|
management/web-console.war
|
|
|
JSR-77
|
management/console-mgr.sar
|
|
|
Monitoring mail alerts
|
monitoring-service.xml
|
jboss-monitoring.jar
|
|
Schedule Manager
|
schedule-manager-service.xml
|
scheduler-plugin.jar, scheduler-plugin-example.jar
|
|
Sample Schedule service
|
scheduler-service.xml
|
If you are removing a core JBoss service like JMS or EAR Deployer then you need to remove it also from the jboss-service.xml :
<mbean code="org.jboss.management.j2ee.LocalJBossServerDomain" name="jboss.management.local:j2eeType=J2EEDomain,name=Manager"> <attribute name="MainDeployer">jboss.system:service=MainDeployer</attribute> <attribute name="SARDeployer">jboss.system:service=ServiceDeployer</attribute> <attribute name="EARDeployer">jboss.j2ee:service=EARDeployer</attribute> <attribute name="EJBDeployer">jboss.ejb:service=EJBDeployer</attribute> <attribute name="RARDeployer">jboss.jca:service=RARDeployer</attribute> <attribute name="CMDeployer">jboss.jca:service=ConnectionFactoryDeployer</attribute> <attribute name="WARDeployer">jboss.web:service=WebServer</attribute> <attribute name="CARDeployer">jboss.j2ee:service=ClientDeployer</attribute> <attribute name="MailService">jboss:service=Mail</attribute> <attribute name="JMSService">jboss.mq:service=DestinationManager</attribute> <attribute name="JNDIService">jboss:service=Naming</attribute> <attribute name="JTAService">jboss:service=TransactionManager</attribute> <attribute name="UserTransactionService">jboss:service=ClientUserTransaction</attribute> <attribute name="RMI_IIOPService">jboss:service=CorbaORB</attribute> </mbean>
Simply comment the attribute relative to the unwanted service
Make Log4j silent !
Wel not really anyway Log4j uses a valuable amount of time/CPU so you had better remove unnecessary logs, for example :
- Remove logs from Console
Comment the following line in log4j.xml in order to remove logs on the Console:
<root> <!-- <appender-ref ref=CONSOLE"></appender-ref> --> <appender-ref ref="FILE"></appender-ref> </root>
Also remove its appender:
<appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender"> .... </appender>
- Raise log priority
Consider raising the log level to the highest level possible in production. Here only error logs are written:
<root>
<priority value="ERROR" />
<!--<appender-ref ref="CONSOLE"></appender-ref> -->
<appender-ref ref="FILE" />
</root>
Hungry for Tuning?
Speed-up your Enterprise Applications with our WildFly Performance Tuning guide!
