Clustering means that when your application is running on a server, it can continue its task on another server exactly at the same point it was at, without any manual failover. This means that the application’s state is replicated across cluster members.
The following picture shows WildFly clustering building blocks:
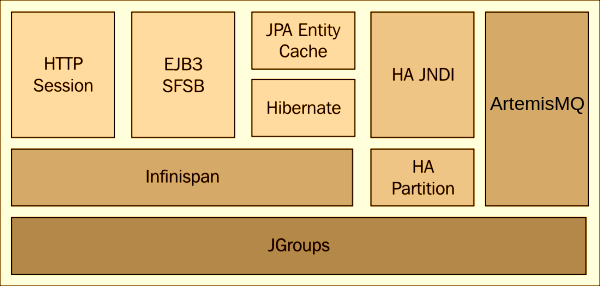
As you can see, the backbone of WildFly clustering is the JGroups library, which provides a reliable multicast system used by cluster members to find each other and communicate. Next comes Infinispan, which is a data grid platform that is used by the application server to keep in sync the application data in the cluster by means of a replicated and transactional JSR-107 compatible cache. Infinispan is used both as a Cache for standard session mechanisms (HTTP Sessions and SFSB session data) and as advanced caching mechanism for JPA and Hibernate objects (aka second level cache).
Clustering WildFly in Standalone mode
To start WildFly in High Availability you can use one of the following profiles:
- ha: clustering of EJB and Web applications
- full-ha: : clustering of EJB, Web applications and JMS applications
The simplest way to start a cluster in standalone mode is therefore to use a configuration that is cluster-aware, for example:
$ ./standalone.sh -c standalone-ha.xml
Next, from another console another instance of WildFly, using a port offset to avoid clashing with the ports opened by the first server:
$ ./standalone.sh -c standalone-ha.xml -Djboss.socket.binding.port-offset=100
As JGroups is a subsystem that gets activated on demand, if no clusterable applications are deployed the cluster won’t be created.
Next, deploy any cluster-aware application. For example, an EJB application. You will see that the JGroups ejb channel starts and Infinispan elaborates a new cluster view:
2019-01-11 16:49:55,815 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-5) ISPN000078: Starting JGroups channel ejb 2019-01-11 16:49:55,815 INFO [org.infinispan.remoting.transport.jgroups.JGroupsTransport] (MSC service thread 1-8) ISPN000078: Starting JGroups channel ejb 2019-01-11 16:49:55,822 INFO [org.infinispan.CLUSTER] (MSC service thread 1-5) ISPN000094: Received new cluster view for channel ejb: [standalone-1/web|1] [standalone-1/ejb, standalone-2/ejb]
Internally, the communication within the cluster is managed by JGroups in its own subsystem:
<subsystem xmlns="urn:jboss:domain:jgroups:9.0">
<channels default="ee">
<channel name="ee" stack="udp" cluster="ejb"/>
</channels>
<stacks>
<stack name="udp">
<transport type="UDP" socket-binding="jgroups-udp"/>
<protocol type="RED"/>
<protocol type="PING"/>
<protocol type="MERGE3"/>
<socket-protocol type="FD_SOCK2" socket-binding="jgroups-udp-fd"/>
<protocol type="FD_ALL3"/>
<protocol type="VERIFY_SUSPECT2"/>
<protocol type="pbcast.NAKACK2"/>
<protocol type="UNICAST3"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG4"/>
</stack>
<stack name="tcp">
<transport type="TCP" socket-binding="jgroups-tcp"/>
<protocol type="RED"/>
<socket-protocol type="MPING" socket-binding="jgroups-mping"/>
<protocol type="MERGE3"/>
<socket-protocol type="FD_SOCK2" socket-binding="jgroups-tcp-fd"/>
<protocol type="FD_ALL3"/>
<protocol type="VERIFY_SUSPECT2"/>
<protocol type="pbcast.NAKACK2"/>
<protocol type="UNICAST3"/>
<protocol type="pbcast.STABLE"/>
<protocol type="pbcast.GMS"/>
<protocol type="UFC"/>
<protocol type="MFC"/>
<protocol type="FRAG4"/>
</stack>
</stacks>
</subsystem>
As you can see, JGroups provides by default two different stacks, named “udp” and “tcp” , each one with its own particular protocol stack. By default JGroups is configured to use UDP and multicasting, for discovering members and to communicate / verify their state. If you want to switch to a pure TCP clustering solution we recommend reading this tutorial: How to configure WildFly and JBoss EAP to use TCPPING
While JGroups handle the communication between cluster members, the Session data of the cluster itself is managed by Infinispan subsystem.
<subsystem xmlns="urn:jboss:domain:infinispan:14.0">
<cache-container name="ejb" default-cache="dist" marshaller="PROTOSTREAM" aliases="sfsb" modules="org.wildfly.clustering.ejb.infinispan">
<transport lock-timeout="60000"/>
<local-cache name="transient">
<locking isolation="REPEATABLE_READ"/>
<transaction mode="BATCH"/>
<expiration interval="0"/>
<file-store passivation="true" purge="true"/>
</local-cache>
<replicated-cache name="client-mappings">
<expiration interval="0"/>
</replicated-cache>
<distributed-cache name="dist">
<locking isolation="REPEATABLE_READ"/>
<transaction mode="BATCH"/>
<expiration interval="0"/>
<file-store passivation="true" purge="true"/>
</distributed-cache>
<distributed-cache name="persistent">
<locking isolation="REPEATABLE_READ"/>
<transaction mode="BATCH"/>
<expiration interval="0"/>
<file-store passivation="true"/>
</distributed-cache>
</cache-container>
<cache-container name="hibernate" marshaller="JBOSS" modules="org.infinispan.hibernate-cache">
<transport lock-timeout="60000"/>
<local-cache name="local-query">
<heap-memory size="10000"/>
<expiration max-idle="100000"/>
</local-cache>
<local-cache name="pending-puts">
<expiration max-idle="60000"/>
</local-cache>
<invalidation-cache name="entity">
<heap-memory size="10000"/>
<expiration max-idle="100000"/>
</invalidation-cache>
<replicated-cache name="timestamps">
<expiration interval="0"/>
</replicated-cache>
</cache-container>
<cache-container name="web" default-cache="dist" marshaller="PROTOSTREAM" modules="org.wildfly.clustering.web.infinispan">
<transport lock-timeout="60000"/>
<replicated-cache name="sso">
<locking isolation="REPEATABLE_READ"/>
<transaction mode="BATCH"/>
<expiration interval="0"/>
</replicated-cache>
<replicated-cache name="routing">
<expiration interval="0"/>
</replicated-cache>
<distributed-cache name="dist">
<locking isolation="REPEATABLE_READ"/>
<transaction mode="BATCH"/>
<expiration interval="0"/>
<file-store passivation="true" purge="true"/>
</distributed-cache>
</cache-container>
<cache-container name="server" default-cache="default" marshaller="PROTOSTREAM" aliases="singleton cluster" modules="org.wildfly.clustering.singleton.server">
<transport lock-timeout="60000"/>
<replicated-cache name="default">
<transaction mode="BATCH"/>
<expiration interval="0"/>
</replicated-cache>
</cache-container>
</subsystem>
As you can see, three cache containers are relevant for storing the session state of your applications:
- The “ejb” cache holds Stateful Session Beans
- The “web” cache holds HTTP Session data across the cluster
- The “hibernate” caches stores the Entity and the Query objects
Clustering in Domain Mode
The same concepts apply to the domain mode, which means that to get clustering capabilities, we need to choose between the ha or full-ha profile.
As you already know, in domain mode, all the available and configured profiles reside in a single file, domain.xml . Each profile is then referenced by one or more server-groups. So, in order to configure the “main-server-group” to be cluster-aware switch to the “ha” or “full-ha” profile as in this example:
<server-groups>
<server-group name="main-server-group" profile="ha">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="ha-sockets"/>
</server-group>
<server-group name="other-server-group" profile="full-ha">
<jvm name="default">
<heap size="64m" max-size="512m"/>
</jvm>
<socket-binding-group ref="full-ha-sockets"/>
</server-group>
</server-groups>
Conclusion
In conclusion, clustering WildFly, whether in standalone mode or domain mode, provides powerful capabilities for achieving high availability, scalability, and fault tolerance in enterprise applications.
Standalone mode clustering enables the deployment of multiple WildFly instances on different machines, sharing the same application and providing load balancing across the cluster. It ensures that if one instance fails, the others can seamlessly take over the workload, enhancing system reliability. Additionally, standalone mode clustering offers flexibility in configuring and managing individual instances while still benefiting from clustering capabilities.
Domain mode clustering takes the clustering capabilities to the next level by providing centralized management and configuration of multiple WildFly server groups. It allows the distribution of applications and configurations across different server groups, facilitating efficient resource utilization and easier management of large-scale deployments. Domain mode clustering also supports domain-wide deployment and centralized monitoring, making it an ideal choice for complex enterprise environments.