There are over 70 Java-based open source machine learning projects listed on the MLOSS.org website, and probably many more unlisted projects live at university servers, GitHub, or Bitbucket. In this article, we will review the major libraries and platforms, the kind of problems they can solve, the algorithms they support, and the kind of data they can work with.
Weka
Waikato Environment for Knowledge Analysis (WEKA) is a machine learning library that was developed at the University of Waikato, New Zealand, and is probably the most well-known Java library. It is a general purpose library that is able to solve a wide variety of machine learning tasks, such as classification, regression, and clustering. It features a rich graphical user interface, command-line interface, and Java API. You can check out Weka at http://www.cs.waikato.ac.nz/ml/weka/.

Currently, Weka contains 267 algorithms in total: data preprocessing (82), attribute selection (33), classification and regression (133), clustering (12), and association rules mining (7). Graphical interfaces are well suited for exploring your data, while the Java API allows you to develop new machine learning schemes and use the algorithms in your applications.
Weka is distributed under the GNU General Public License (GNU GPL), which means that you can copy, distribute, and modify it as long as you track changes in source files and keep it under GNU GPL. You can even distribute it commercially, but you must disclose the source code or obtain a commercial license.
In addition to several supported file formats, Weka features its own default data format, ARFF, to describe data by attribute-data pairs. It consists of two parts. The first part contains a header, which specifies all of the attributes and their types, for instance, nominal, numeric, date, and string. The second part contains the data, where each line corresponds to an instance. The last attribute in the header is implicitly considered the target variable and missing data is marked with a question mark. Consider the following example:
@RELATION person_dataset
@ATTRIBUTE `Name` STRING
@ATTRIBUTE `Height` NUMERIC
@ATTRIBUTE `Eye color`{blue, brown, green}
@ATTRIBUTE `Hobbies` STRING @DATA 'Bob', 185.0, blue, 'climbing, sky diving' 'Anna', 163.0, brown, 'reading' 'Jane', 168.0, ?, ?
The file consists of three sections. The first section starts with the @RELATION keyword, specifying the dataset name. The next section starts with the @ATTRIBUTE keyword, followed by the attribute name and type. The available types are STRING, NUMERIC, DATE, and a set of categorical values. The last attribute is implicitly assumed to be the target variable that we want to predict. The last section starts with the @DATA keyword, followed by one instance per line. Instance values are separated by commas and must follow the same order as attributes in the second section.
Weka’s Java API is organized into the following top-level packages:
- weka.associations: These are data structures and algorithms for association rules learning, including Apriori, predictive Apriori, FilteredAssociator, FP-Growth, Generalized Sequential Patterns (GSP), hotSpot, and Tertius.
- weka.classifiers: These are supervised learning algorithms, evaluators, and data structures. The package is further split into the following components:
- weka.classifiers.bayes: This implements Bayesian methods, including Naive Bayes, Bayes net, Bayesian logistic regression, and so on.
- weka.classifiers.evaluation: These are supervised evaluation algorithms for nominal and numerical prediction, such as evaluation statistics, confusion matrix, ROC curve, and so on.
- weka.classifiers.functions: These are regression algorithms, including linear regression, isotonic regression, Gaussian processes, Support Vector Machines (SVMs), multilayer perceptron, voted perceptron, and others..weka.classifiers.lazy: These are instance-based algorithms such as k-nearest neighbors, K*, and lazy Bayesian rules.
- weka.classifiers.meta: These are supervised learning meta-algorithms, including AdaBoost, bagging, additive regression, random committee, and so on.
- weka.classifiers.mi: These are multiple-instance learning algorithms, such as citation k-nearest neighbors, diverse density, AdaBoost, and others.
- weka.classifiers.rules: These are decision tables and decision rules based on the separate-and-conquer approach, RIPPER, PART, PRISM, and so on.
- weka.classifiers.trees: These are various decision trees algorithms, including ID3, C4.5, M5, functional tree, logistic tree, random forest, and so on.
- weka.clusterers: These are clustering algorithms, including k-means, CLOPE, Cobweb, DBSCAN hierarchical clustering, and FarthestFirst.
- weka.core: These are various utility classes such as the attribute class, statistics class, and instance class.
- weka.datagenerators: These are data generators for classification, regression, and clustering algorithms.
- weka.estimators: These are various data distribution estimators for discrete/nominal domains, conditional probability estimations, and so on.
- weka.experiment: These are a set of classes supporting necessary configuration, datasets, model setups, and statistics to run experiments.
- weka.filters: These are attribute-based and instance-based selection algorithms for both supervised and unsupervised data preprocessing.
- weka.gui: These are graphical interface implementing explorer, experimenter, and knowledge flow applications. The Weka Explorer allows you to investigate datasets, algorithms, as well as their parameters, and visualize datasets with scatter plots and other visualizations. The Weka Experimenter is used to design batches of experiments, but it can only be used for classification and regression problems.The Weka KnowledgeFlow implements a visual drag-and-drop user interface to build data flows and, for example, load data, apply filter, build classifier, and evaluate it.
Java Machine Learning Library
The Java Machine Learning Library (Java-ML) is a collection of machine learning algorithms with a common interface for algorithms of the same type. It only features the Java API, and so it is primarily aimed at software engineers and programmers. Java-ML contains algorithms for data preprocessing, feature selection, classification, and clustering. In addition, it features several Weka bridges to access Weka’s algorithms directly through the Java-ML API. It can be downloaded from http://java-ml.sourceforge.net.

Java-ML is also a general-purpose machine learning library. Compared to Weka, it offers more consistent interfaces and implementations of recent algorithms that are not present in other packages, such as an extensive set of state-of-the-art similarity measures and feature-selection techniques, for example, dynamic time warping (DTW), random forest attribute evaluation, and so on. Java-ML is also available under the GNU GPL license.
Java-ML supports all types of files as long as they contain one data sample per line and the features are separated by a symbol such as a comma, semicolon, or tab. The library is organized around the following top-level packages:
- net.sf.javaml.classification: These are classification algorithms, including Naive Bayes, random forests, bagging, self-organizing maps, k-nearest neighbors, and so on
- net.sf.javaml.clustering: These are clustering algorithms such as k-means, self-organizing maps, spatial clustering, Cobweb, ABC, and others
- net.sf.javaml.core: These are classes representing instances and datasets
- net.sf.javaml.distance: These are algorithms that measure instance distance and similarity, for example, Chebyshev distance, cosine distance/similarity, Euclidean distance, Jaccard distance/similarity, Mahalanobis distance, Manhattan distance, Minkowski distance, Pearson correlation coefficient, Spearman’s footrule distance, DTW, and so on
- net.sf.javaml.featureselection: These are algorithms for feature evaluation, scoring, selection, and ranking, for instance, gain ratio, ReliefF, Kullback-Leibler divergence, symmetrical uncertainty, and so on
- net.sf.javaml.filter: These are methods for manipulating instances by filtering, removing attributes, setting classes or attribute values, and so on
- net.sf.javaml.matrix: This implements in-memory or file-based arrays
- net.sf.javaml.sampling: This implements sampling algorithms to select a subset of datasets
- net.sf.javaml.tools: These are utility methods on dataset, instance manipulation, serialization, Weka API interface, and so on
- net.sf.javaml.utils: These are utility methods for algorithms, for example, statistics, math methods, contingency tables, and others
Apache Mahout
The Apache Mahout project aims to build a scalable machine learning library. It is built atop scalable, distributed architectures, such as Hadoop, using the MapReduce paradigm, which is an approach for processing and generating large datasets with a parallel, distributed algorithm using a cluster of servers.
Mahout features a console interface and the Java API as scalable algorithms for clustering, classification, and collaborative filtering. It is able to solve three business problems:
- Item recommendation: Recommending items such as People who liked this movie also liked
- Clustering: Sorting of text documents into groups of topically-related documents
- Classification: Learning which topic to assign to an unlabelled document
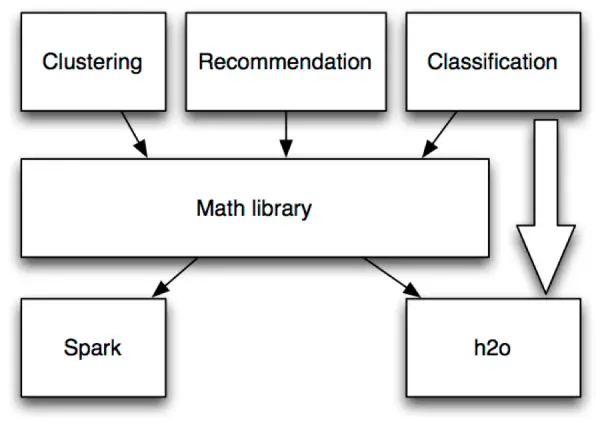
Mahout features the following libraries:
- org.apache.mahout.cf.taste: These are collaborative filtering algorithms based on user-based and item-based collaborative filtering and matrix factorization with ALS
- org.apache.mahout.classifier: These are in-memory and distributed implementations, including logistic regression, Naive Bayes, random forest, hidden Markov models (HMM), and multilayer perceptron
- org.apache.mahout.clustering: These are clustering algorithms such as canopy clustering, k-means, fuzzy k-means, streaming k-means, and spectral clustering
- org.apache.mahout.common: These are utility methods for algorithms, including distances, MapReduce operations, iterators, and so on
- org.apache.mahout.driver: This implements a general-purpose driver to run main methods of other classes
- org.apache.mahout.ep: This is the evolutionary optimization using the recorded-step mutation
- org.apache.mahout.math: These are various math utility methods and implementations in Hadoop
- org.apache.mahout.vectorizer: These are classes for data presentation, manipulation, and MapReduce jobs
Apache Spark
Apache Spark, or simply Spark, is a platform for large-scale data processing builds atop Hadoop, but, in contrast to Mahout, it is not tied to the MapReduce paradigm. Instead, it uses in-memory caches to extract a working set of data, process it, and repeat the query. This is reported to be up to ten times as fast as a Mahout implementation that works directly with data stored in the disk. It can be grabbed from https://spark.apache.org.
There are many modules built atop Spark, for instance, GraphX for graph processing, Spark Streaming for processing real-time data streams, and MLlib for machine learning library featuring classification, regression, collaborative filtering, clustering, dimensionality reduction, and optimization.

Spark’s MLlib can use a Hadoop-based data source, for example, Hadoop Distributed File System (HDFS) or HBase, as well as local files. The supported data types include the following:
Local vectors are stored on a single machine. Dense vectors are presented as an array of double-typed values, for example, (2.0, 0.0, 1.0, 0.0), while sparse vector is presented by the size of the vector, an array of indices, and an array of values, for example, [4, (0, 2), (2.0, 1.0)].
Labelled point is used for supervised learning algorithms and consists of a local vector labelled with double-typed class values. The label can be a class index, binary outcome, or a list of multiple class indices (multiclass classification). For example, a labelled dense vector is presented as [1.0, (2.0, 0.0, 1.0, 0.0)].
Local matrices store a dense matrix on a single machine. It is defined by matrix dimensions and a single double-array arranged in a column-major order.
Distributed matrices operate on data stored in Spark’s Resilient Distributed Dataset (RDD), which represents a collection of elements that can be operated on in parallel. There are three presentations: row matrix, where each row is a local vector that can be stored on a single machine, row indices are meaningless; indexed row matrix, which is similar to row matrix, but the row indices are meaningful, that is, rows can be identified and joins can be executed; and coordinate matrix, which is used when a row cannot be stored on a single machine and the matrix is very sparse.
Spark’s MLlib API library provides interfaces for various learning algorithms and utilities, as outlined in the following list:
- org.apache.spark.mllib.classification: These are binary and multiclass classification algorithms, including linear SVMs, logistic regression, decision trees, and Naive Bayes
- org.apache.spark.mllib.clustering: These are k-means clustering algorithms
- org.apache.spark.mllib.linalg: These are data presentations, including dense vectors, sparse vectors, and matrices
- org.apache.spark.mllib.optimization: These are the various optimization algorithms that are used as low-level primitives in MLlib, including gradient descent, stochastic gradient descent (SGD), update schemes for distributed SGD, and the limited-memory Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm
- org.apache.spark.mllib.recommendation: These are model-based collaborative filtering techniques implemented with alternating least squares matrix factorization
- org.apache.spark.mllib.regression: These are regression learning algorithms, such as linear least squares, decision trees, Lasso, and Ridge regression
- org.apache.spark.mllib.stat: These are statistical functions for samples in sparse or dense vector format to compute the mean, variance, minimum, maximum, counts, and nonzero counts
- org.apache.spark.mllib.tree: This implements classification and regression decision tree-learning algorithms
- org.apache.spark.mllib.util: These are a collection of methods used for loading, saving, preprocessing, generating, and validating the data
Learn more
If you found this article helpful and would want to learn more about machine learning with Java, you can explore Machine Learning in Java – Second Edition. Written by Ashish Singh Bhatia and Bostijan Kaluza, Machine Learning in Java – Second Edition, will provide you with the techniques and tools you need to quickly gain insight from complex data.
Found the article helpful? if so please follow us on Socials



