What you like to have a close look over the Infinispan distribution of data in your JBoss EAP 6 / WildFly cluster? I’ll tell you how to do it.
The default algorithm used by WildFly application server for clustering is based on the Infinispan distribution. This means that cache entries are copied to a fixed number of cluster nodes (2, by default) regardless of the cluster size. Distribution uses a consistent hashing algorithm to determine which nodes will store a given entry.
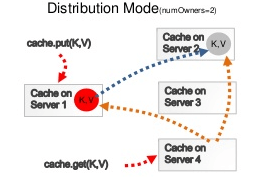
Caches in turn are available to the application server in the form of Cache containers. Some of them are already available in the infinispan configuration such as the web cache and the ejb cache and they can be retrieved in your application as follows:
@Resource(lookup="java:jboss/infinispan/container/web") private CacheContainer container;
Now we will show how to create a simple Web application which stores the keys in the HTTP Session, then we show in a table where keys are located in the server and the server elected as primary server.
Let’s build a simple EJB which can be used for this purpose:
@Stateless
public class CacheInspector {
@Resource(lookup="java:jboss/infinispan/container/web")
private CacheContainer container;
private org.infinispan.Cache<String, String> cache;
@PostConstruct
public void init() {
this.cache = container.getCache();
}
public String locateServers(String key) {
List<Address> list = this.cache.getAdvancedCache().getDistributionManager().locate(key);
if (list != null)
return
list.toString();
else return null;
}
public String locatePrimary(String key) {
Object list = this.cache.getAdvancedCache().getDistributionManager().getPrimaryLocation(key);
if (list != null)
return
list.toString();
else return null;
}
}
The locateServers method is used to retrieve the list of Servers where a particular key is stored. The number of elements in the List<Address> corresponds to the owners in the infinispan configuration. To keep it simple we return the ArrayList as a String of servers.
The locatePrimary method, on the other hand, returns the Node which has been elected as primary node in the cluster.
Our application is almost ready, all we need is some “glue” to reach out the EJB:
@RequestScoped
@ManagedBean
public class Bean {
private String key;
private String value;
List propertyList = new ArrayList();
@EJB CacheInspector ejb;
// Getter/setters here
public void save() {
FacesContext facesContext = FacesContext.getCurrentInstance();
HttpSession session = (HttpSession) facesContext.getExternalContext()
.getSession(false);
session.setAttribute(key, value);
propertyList = new ArrayList();
Enumeration e = session.getAttributeNames();
while (e.hasMoreElements()) {
String attr = (String) e.nextElement();
Item item = new Item();
item.setKey(attr);
item.setValue(session.getAttribute(attr).toString());
String location = ejb.locateServers(attr);
String primary = ejb.locatePrimary(attr);
item.setServers(location);
item.setPrimary(primary);
propertyList.add(item);
}
}
}
And finally a simple view to add some key/values in the HttpSession, through the save method of the Bean class:
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:ui="http://java.sun.com/jsf/facelets"
xmlns:h="http://java.sun.com/jsf/html"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:c="http://java.sun.com/jsp/jstl/core">
<h:head>
<style type="text/css">
</style>
</h:head>
<h:body>
<h2>Cache distribution demo</h2>
<h:form id="jsfexample">
<h:panelGrid columns="2" styleClass="default">
<h:outputText value="Enter key:" />
<h:inputText value="#{bean.key}" />
<h:outputText value="Enter value:" />
<h:inputText value="#{bean.value}" />
<h:commandButton actionListener="#{bean.save}"
styleClass="buttons" value="Save key/value" />
<h:messages />
</h:panelGrid>
<h:dataTable value="#{bean.propertyList}" var="item"
styleClass="table" headerClass="table-header"
rowClasses="table-odd-row,table-even-row">
<h:column>
<f:facet name="header">Key</f:facet>
<h:outputText value="#{item.key}" />
</h:column>
<h:column>
<f:facet name="header">Location</f:facet>
<h:outputText value="#{item.servers}" />
</h:column>
<h:column>
<f:facet name="header">Primary</f:facet>
<h:outputText value="#{item.primary}" />
</h:column>
</h:dataTable>
</h:form>
</h:body>
</html>
Our application is ready so let’s start a JBoss EAP 6 – WildFly in HA mode with a couple of nodes. Deploy the application and start adding some entries:
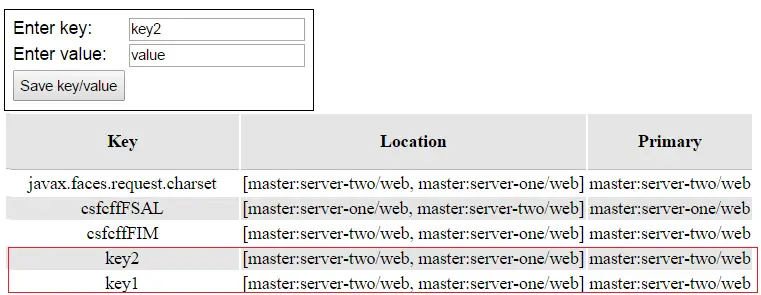
As you can see from the above picture, with only two servers and owners=2 the distribution acts like a replication. If we add some more nodes to the cluster you can see that each key is available just on two nodes (out of the four nodes of the cluster):
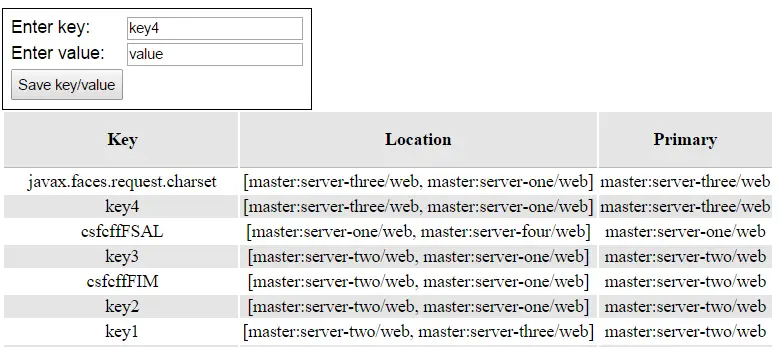
You can use the above code as foundation for learning the algorithms used by Infinispan to distribute cache entries and how they can be influenced by setting server hints in the JGroups transport section. Have fun with distribution!
Found the article helpful? if so please follow us on Socials


