WildFly ships with the subsystem batch-jberet which is the administration side of JSR 352, also known as Batch API for Java applications. This JSR specifies a programming model for batch applications and a runtime for scheduling and executing jobs.
WildFly Batch Job Repository configuration
Out of the box, the following configuration defines the batch-jberet subsystem:
<subsystem xmlns="urn:jboss:domain:batch-jberet:3.0">
<default-job-repository name="in-memory"/>
<default-thread-pool name="batch"/>
<job-repository name="in-memory">
<in-memory/>
</job-repository>
<thread-pool name="batch">
<max-threads count="10"/>
<keepalive-time time="30" unit="seconds"/>
</thread-pool>
</subsystem>
As you can see from the above configurations, batch-jberet fires Job executions in a repository, which enables querying of current and historical job status. The default location of the job repository is in-memory which means that you can query the repository programmatically using the Batch API.
On the other hand, if you want to inspect the Job Repository using typical administration tools, then you can opt for using a JDBC Repository which can then be queried using standard SQL commands.
Another important advantage of using a JDBC Job Repository is that you will be able to restart your jobs from the point they left off, in case of application server failure.
Setting the job repository to use JDBC is just a matter of executing a couple of CLI commands:
/subsystem=batch-jberet/jdbc-job-repository=jdbc-repository:add(data-source=PostgrePool) /subsystem=batch-jberet:write-attribute(name=default-job-repository,value=jdbc-repository)
As you can see, the jdbc-repository points to the datasource PostgrePool. Therefore, you need to have in your datasource configuration a resource with that name:
<datasource jndi-name="java:/PostGreDS" pool-name="PostgrePool">
<connection-url>jdbc:postgresql://localhost:5432/jbpm</connection-url>
<driver>postgres</driver>
<security>
<user-name>postgres</user-name>
<password>jbpm</password>
</security>
</datasource>
<drivers>
<driver name="postgres" module="org.postgres">
<driver-class>org.postgresql.Driver</driver-class>
</driver>
</drivers>
Once that initialize the Batch API with some jobs, the tables will be automatically created:
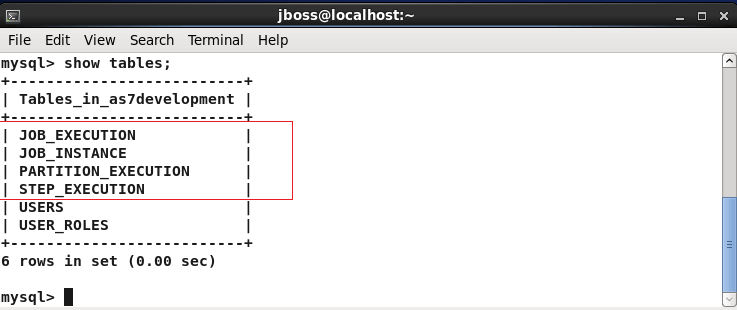
You can query for the Jobs which have been executed by a particular application through the JOB_INSTANCE table: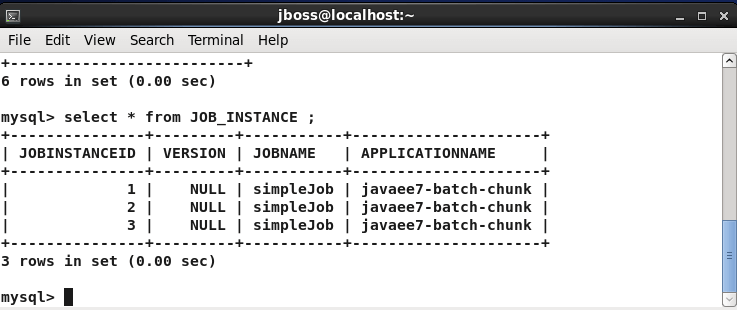
On the other hand if you want some execution details about jobs, then you can query the JOB_EXECUTION table: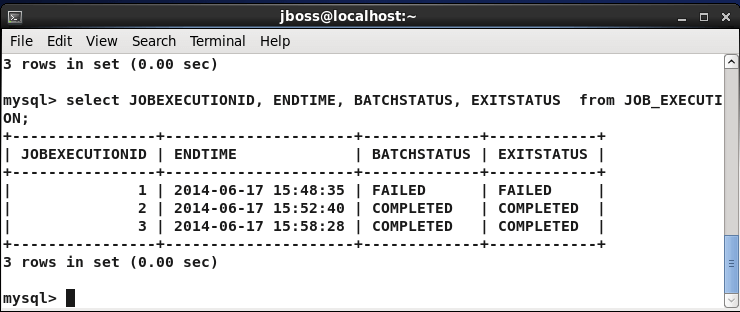
Conclusion
By following best practices and leveraging the flexibility offered by WildFly, you can build robust batch processing solutions that scale seamlessly and deliver optimal performance. Whether you’re handling large-scale data processing or periodic background tasks, the WildFly Batch Job Repository empowers you to manage your batch jobs effectively, contributing to the overall success and responsiveness of your enterprise applications.
Found the article helpful? if so please follow us on Socials


