By using Buddy replication, sessions are replicated to a configurable number of backup servers in the cluster (also called buddies), rather than to all servers in the cluster. If a user fails over from the server that is hosting his or her session, the session data is transferred to the new server from one of the backup buddies.
Overview of Buddy replication
That being said, if you are running an old JBoss release, let’s check the benefits of using Buddy replication:
- Reduced memory usage
- Reduced CPU utilization
- Reduced network transmission
The reason behind this large set of advantages is that each server only needs to store in its memory the sessions it is hosting as well as those of the servers for which it is acting as a backup. Thus, less memory required to store data, less CPU to elaborate bits to Java translations, and less data to transmit.
For example, in an 8-node cluster with each server configured to have one buddy, a server would just need to store 2 sessions instead of 8. That’s just one fourth of the memory required with total replication.
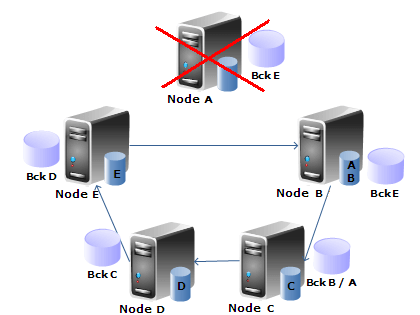
In the following picture, you can see an example of a cluster confi gured for buddy replication:

Here, each node contains a cache of its session data and a backup of another node.
For example, node A contains its session data and a backup of node E. Its data is in turn replicated to node B and so on.
In case of failure of node A, its data moves to node B which becomes the owner of both A and B data, plus the backup of node E. Node B in turn replicates (A + B) data to node C.
Enabling buddy replication
In order to configure your SFSB sessions or HttpSessions to use buddy replication you have just to set to the property enabled of the bean BuddyReplicationConfig inside the <server>/deploy/cluster/jboss-cache-manager.sar/META-INF/jboss-cache-manager-jboss-beans.xml configuration file, as shown in the next code fragment:
<property name="buddyReplicationConfig"> <bean class="org.jboss.cache.config.BuddyReplicationConfig"> <property name="enabled">true</property> . . . </bean> </property>
In the following test, we are comparing the throughput of a 5-node clustered web application which uses buddy replication against one which replicates data across all members of the cluster.
In this benchmark, switching on buddy replication improved the application throughput of about 30%. No doubt that by using buddy replication there’s a high potential for scaling because memory/CPU/network usage per node does not increase linearly as new nodes are added.

Advanced buddy replication
With the minimal configuration we have just described, each server will look for one buddy across the network where data needs to be replicated. If you need to backup your session to a larger set of buddies you can modify the numBuddies property of the BuddyReplicationConfig bean.
Consider, however, that replicating the session to a large set of nodes would conversely reduce the benefits of buddy replication.
Still using the default configuration, each node will try to select its buddy on a different physical host: this helps to reduce chances of introducing a single point of failure in your cluster. Just in case the cluster node is not able to fi nd buddies on different physical hosts, it will not honour the property ignoreColocatedBuddies and fall back to co-located nodes.
The default policy is often what you might need in your applications, however if you need a fine-grained control over the composition of your buddies you can use a feature named buddy pool.
A buddy pool is an optional construct where each instance in a cluster may be confi gured to be part of a group- just like an “exclusive club membership”.
This allows system administrators a degree of flexibility and control over how buddies are selected. For example, you might put two instances on separate physical servers that may be on two separate physical racks in the same buddy pool. So rather than picking an instance on a different host on the same rack, the BuddyLocators would rather pick the instance in the same buddy pool, on a separate rack which may add a degree of redundancy.
Here’s a complete confi guration which includes buddy pools:
<property name="buddyReplicationConfig"> <bean class="org.jboss.cache.config.BuddyReplicationConfig"> <property name="enabled">true</property> <property name="buddyPoolName">rack1</property> <property name="buddyCommunicationTimeout">17500</property> <property name="autoDataGravitation">false</property> <property name="dataGravitationRemoveOnFind">true</property> <property name="dataGravitationSearchBackupTrees">true</property> <property name="buddyLocatorConfig"> <bean class="org.jboss.cache.buddyreplication.NextMemberBuddyLocatorConfig" > <property name="numBuddies">1</property> <property name="ignoreColocatedBuddies">true</property> </bean> </property> </bean> </property>
In this configuration fragment, the buddyPoolName element, if specified, creates a logical subgroup and only picks buddies who share the same buddy pool name. If not specified, this defaults to an internal constant name, which then treats the entire cluster as a single buddy pool.
If the cache on another node needs data that it doesn’t have locally, it can ask the other nodes in the cluster to provide it; nodes that have a copy will provide it as part of a process called data gravitation. The new node will become the owner of the data, placing a backup copy of the data on its buddies.
The ability to gravitate data means there is no need for all requests for data to occur on a node that has a copy of it; that is, any node can handle a request for any data.
However, data gravitation is expensive and should not be a frequent occurrence;
ideally it should only occur if the node that is using some data fails or is shut down, forcing interested clients to fail over to a different node.
The following optional properties pertain to data gravitation:
• autoDataGravitation: Whether data gravitation occurs for every cache miss. By default this is set to false to prevent unnecessary network calls.
• DataGravitationRemoveOnFind: Forces all remote caches that own the data or hold backups for the data to remove that data, thereby making the requesting cache the new data owner. If set to false, an evict is broadcast instead of a remove, so any state persisted in cache loaders will remain. This is useful if you have a shared cache loader confi gured. (See next section about Cache loader). Defaults to true.
• dataGravitationSearchBackupTrees: Asks remote instances to search through their backups as well as main data trees. Defaults to true. The resulting effect is that if this is true then backup nodes can respond to data gravitation requests in addition to data owners.
Buddy replication and session affinity
One of the pre-requisites to buddy replication working well and being a real benefit is the use of session affi nity, also known as sticky sessions in HttpSession replication speak. What this means is that if certain data is frequently accessed, it is desirable that this is always accessed on one instance rather than in a “round-robin” fashion as this helps the cache cluster optimise how it chooses buddies, where it stores data, and minimises replication traffic.
If you are replicating SFSBs session, there is no need to configure anything since SFSBs, once created, are pinned to the server that created them.
When using HttpSession, you need to make sure your software or hardware load balancer maintain the session on the same host where it was created.
By using Apache’s mod_jk, you have to confi gure the workers file (workers.properties) specifying where the different node and how calls should be load-balanced across them. For example, on a 5-node cluster:
worker.loadbalancer.balance_workers=node1,node2,node3,node4,node5 worker.loadbalancer.sticky_session=1
Basically, the above snippet configures mod_jk to perform round-robin load balancing with sticky sessions (sticky_session=1) across 5 nodes of a cluster.
Found the article helpful? if so please follow us on Socials


