Warning: this tutorial has been written for an old version of Infinispan and it's now obsolete. We recommend to check the following tutorials to get started quickly with Infinispan: What is Infinispan ? a quick introduction Getting Started with Infinispan data grid -the right way Clustering Infinispan made simple
In this tutorial we will cover some advanced aspects related to Infinispan cache stores, transactions, data eviction and clustering.
Until now we have seen some basic examples of Infinispan’s Local Cache. You might wonder if it makes sense to use Infinispan as Local Cache instead of a simple Hashtable or CuncurrentHashtable. Even if Infinispan focuses on large scale systems, it does make sense to use Infinispan also as Local cache.
For example:
- Infinispan cache has eviction/expiry policies which are built-in. You don’t have to worry about out-of-memory caused by collections growing too much.
- Infinispan has the ability to store cache data on flat File or Jdbc, thus achieving data consistency in the event of system failure.
- Infinispan can be configured to use and to participate in JTA compliant transactions.
- Infinispan has MVCC-based concurrency. Thus it’s highly optimized for fast, non-blocking readers.
- You can monitor and manage Infinispan using JMX or Jopr plugin.
I think we mentioned enough reason why you can benefit of Infinispan even if you are not ready for a Clustered environment.Let’s explore some of this great features:
Using Infinispan Cache Stores
Infinispan can be configured with one or several cache stores allowing it to store data in a persistent location such as shared JDBC database, a local filesystem and others. Using a Cache store requires to define a Cache with a loader element. For example the following define a cache which uses a Flat file Cache store:
<namedCache name="CacheStore"> <loaders passivation="false" shared="false" preload="true"> <loader class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false"> <properties> <property name="location" value="C:\infinispan-4.0.0.FINAL\store"/> </properties> </loader> </loaders> </namedCache>
This can be used to load the custom “CacheStore” configuration and persist one attribute:
CacheManager manager = new DefaultCacheManager("all.xml");
Cache cache = manager.getCache("CacheStore");
cache.put("key", "value");
cache.stop();
manager.stop();
This would produce a file, as soon as the CacheManager is stopped:
By default Cache stores are configured to work synchronously. You can however configure updates to the cache as asynchronously written to the Cache store.
This means that updates to the cache store are done by a separate thread to the client thread interacting with the cache. You can achieve this by adding the async attribute to your loader:
<loader class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false"> . . . . . . <async enabled="true" threadPoolSize="10"/> </loader>
Using Transactions with InfiniSpan
Infinispan can be also configured to participate in JTA compliant transactions. All you need is including in your configuration file one of the TransactionManager classes that ship with Infinispan. For example the following is taken from the sample all.xml configuration:
<transaction transactionManagerLookupClass="org.infinispan.transaction.lookup.GenericTransactionManagerLookup" syncRollbackPhase="false" syncCommitPhase="false" useEagerLocking="false"/>
Implementing a JTA tx requires referencing the “Advanced Cache” from Cache instance as follows:
CacheManager manager = new DefaultCacheManager("all.xml");
Cache cache = manager.getCache();
TransactionManager tm = cache.getAdvancedCache().getTransactionManager();
tm.begin();
cache.put("key", "value");
tm.commit();
Evicting Data from the Cache
Another reason why you should consider using Infinispan over a simple Hashtable caching is the ability to manage the amount of items in the cache using two simple strategies:
Expiration: data is removed from the cache when it reaches a lifespan or it’s idle for too long
Eviction: data is removed from the cache when too many items are added to the cache.
This is a sample configuration which uses eviction:
<namedCache name="evictionCache"> <eviction wakeUpInterval="500" maxEntries="5000" strategy="FIFO" /> <expiration lifespan="60000" maxIdle="1000"/> </namedCache>
Let’s see a trivial example how the cache evicts data if the number of items exceeds maxEntries:
CacheManager cm = new DefaultCacheManager("all.xml");
Cache cache = cm.getCache("evictionCache");
for (int i=0;i<5000;i++) {
cache.put("element"+i, "value"+i);
}
System.out.println("First In Element is " + cache.get("element0"));
cache.put("element5000", "value5000");
System.out.println("Eviction Thread is waking up......");
Thread.sleep(1000);
System.out.println("First In Element is " + cache.get("element0"));
This will result in:
First In Element is value0
Eviction Thread is waking up……
First In Element is null
How to Cluster Infinispan
Infinispan borrows many clustering aspects from JBoss Cache. As a matter of fact, also Infinispan uses JGroups as a network transport and JGroups handles a lot of the hard work of discovery new nodes.
The simplest way to start a cluster node is by means of a simple configuration which includes in the global configuration the cluster name and defines into the default element, the clustering section:
<infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="urn:infinispan:config:5.1 http://www.infinispan.org/schemas/infinispan-config-5.1.xsd" xmlns="urn:infinispan:config:5.1"> <global> <transport clusterName="demoCluster"/> <globalJmxStatistics enabled="true"/> </global> <default> <jmxStatistics enabled="true"/> <clustering mode="distribution"> <hash numOwners="2" rehashRpcTimeout="120000"/> <sync/> </clustering> </default> </infinispan>
Save this file with the name let’s say cluster.xml. Now let’s create a simple application which loads this configuration file and handles a Ticket Booking System:
package com.sample.main;
import java.util.Set;
import org.infinispan.Cache;
import org.infinispan.manager.DefaultCacheManager;
import com.sample.model.Ticket;
import com.sample.utils.IOUtils;
public class SimpleCache {
public void start() throws Exception {
DefaultCacheManager m = new DefaultCacheManager("cluster.xml");
Cache<Integer, Ticket> cache = m.getCache();
String command = null;
int ticketid = 1;
IOUtils.dumpWelcomeMessage();
while (true){
command = IOUtils.readLine("> ");
if (command.equals("book")) {
String name = IOUtils.readLine("Enter name ");
String show = IOUtils.readLine("Enter show ");
Ticket ticket = new Ticket(name,show);
cache.put(ticketid, ticket);
log("Booked ticket "+ticket);
ticketid++;
}
else if (command.equals("pay")) {
Integer id = new Integer(IOUtils.readLine("Enter ticketid "));
Ticket ticket = cache.remove(id);
log("Checked out ticket "+ticket);
}
else if (command.equals("list")) {
Set <Integer> set = cache.keySet();
for (Integer ticket: set) {
System.out.println(cache.get(ticket));
}
}
else if (command.equals("quit")) {
m.stop();
break;
}
else {
log("Unknown command "+command);
IOUtils.dumpWelcomeMessage();
}
}
}
public static void main(String[] args) throws Exception {
new SimpleCache().start();
}
public static void log(String s){
System.out.println(s);
}
}
Now start the application in two separate JVM consoles and verify that once booked a ticket will be visible also on the other JVM console (conversely, if you pay for the ticket, the entry will be removed from the cluster node caches):
Console 1 view: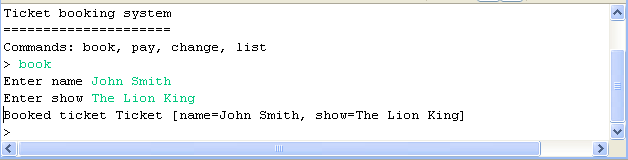
Console 2 view: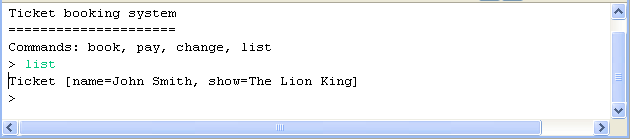
You can download here the full code which includes the Ticket and IOUtils class
Customising Cluster configuration
By using the default configuration you have the basics to start playing with clustering: however you should consider tuning your Cache with a custom cluster configuration. The all.xml sample configuration file (which can be found in the /etc/config-samples dir) contains some templates. For example:
<namedCache name="distributedCache"> <clustering mode="distribution"> <sync/> <hash numOwners="2" rehashWait="120000" rehashRpcTimeout="600000"/> <l1 enabled="true" lifespan="600000"/> </clustering> </namedCache>
Here we have defined a custom Cache named “distributedCache” which is targeted for a clustered environment. Data is distributed among cluster members using a synchronous mode (See element <sync/>).
One interesting configuration parameter is “numOwners” which states the number of owners for each key. The larger this number is, the safer your data will be, but the slower the cluster will be.
In our sample configuration, we have defined to replicate the keys on two nodes of the cluster, so in an hypotetical 4 cluster nodes we would have the following Cache:
The last element in the configuration refers to the L1 cache also known as near cache.
An L1 cache is a distributed cache which is held locally to prevent unnecessary remote fetching of entries. Caches with L1 enabled will consult the L1 cache before fetching an entry from a remote cache.
By default, entries in L1 have a lifespan of 60,000 milliseconds (though you can configure how long L1 entries are cached for). L1 entries are also invalidated when the entry is changed elsewhere in the cluster so you are sure you don’t have stale entries cached in L1.
Here we end our second tutorial about Infinispan. Hope you found this stuff interesting and you want to learn more from the Community documentation. Any feedback as usual is highly welcome!
Found the article helpful? if so please follow us on Socials


